在4月18日举行的的2024联想创新科技大会上,联想集团首席技术官、高级副总裁芮勇博士介绍了大模型到智能体的演进,并解锁了AI新范式的未来方向。清华大学智能产业研究院(AIR)院长、中国工程院院士张亚勤也与芮博士同台,分享了他对大模型发展的独到见解。以下是两位的精彩发言。
4月18日,在刚刚圆满落幕的2024联想创新科技大会(Lenovo Tech World)上,联想集团首席技术官、高级副总裁芮勇博士发表了精彩演讲,介绍了大模型到智能体的演进,并解锁了AI新范式的未来方向。清华大学智能产业研究院(AIR)院长、中国工程院院士张亚勤也与芮博士同台,分享了他对大模型发展的独到见解。以下是两位的精彩发言。
联想CTO芮勇博士发表演讲:
“参加联想创新科技大会的朋友们,大家上午好!从2022年11月,到现在的16个月里,我对人工智能技术有两个观察,想分享给大家。在这16个月里,由大模型引领的人工智能技术可以说是日新月异,有坐地日行八万里的感觉。从百亿参数,到千亿参数,再到万亿参数;从语言模型,到视频模型,再到最近的音乐模型。我的第一个观察就是:AI历史上,无论是统治语音识别30年的隐马尔可夫模型,还是称霸整个90年代的支持向量机,从来没有任何一个技术,能够像今天的大模型这样强大。

大模型,可以说是AI历史上的一个重要里程碑,它开启了人工智能发展的新纪元。但是,正当我们觉得大模型要一统天下的时候,它的局限性也越来越明显。举两个例子,第一,我们在小学学习二元一次方程的时候,都解过鸡兔同笼的问题。互联网上这种训练数据也很多。如果我们直接问大模型普通的鸡兔同笼问题,即使大模型做对了,我们也不知道大模型只是记住了训练数据,还是真正理解了。那我稍微变化一下,在遥远的外星球上,鸡有1个头3只脚,兔子有1个头4只脚。鸡和兔子一共有20个头,71只脚,请问大模型,共有多少只鸡和兔子。这种问题,如果真正理解了,换成几个头几只脚其实都很简单。但是,大模型并没有真正理解,它只知道照葫芦画瓢,并且还画错了,头和脚弄反了。由此来看,大模型的理解和规划能力还有不少局限性。
第二个例子,Sora生成的视频的确非常惊艳,但其实它也存在很多问题。比如这个杯子里的红色饮料,杯子还没有倒,但饮料竟然已经流到桌子上了。今天的大模型不懂得物理规律。总结一下,今天的大模型没有真正理解语言和理解世界,也没有真正的推理和规划能力。它只是根据高维语义空间的联合概率分布,来连接它之前见过的海量信息片段。所以,过去16个月我的第二个观察就是:大模型虽然很强大,但也存在局限性。我们不能再单纯地用大数据+大算力+大网络来堆砌大模型,而是要超越大模型,探索更接近人类的思维和行为方式。
那么,大模型发展的下一步是什么呢?刚才元庆给我们展示了“联想混合式AI框架”。我们可以看见,左侧是大模型,右侧是AI智能体。我们认为,大模型发展的下一步是基于大模型的智能体。大模型一方面能力很强,另一方面有局限性。所以我们要“扬长长短”。“扬长”是我们要持续发扬并增强大模型的强大能力。“长短”是我们要打造基于大模型的智能体技术,真正解决应用场景的问题。我们的理念是我们要左手抓大模型,右手抓智能体,两手都要抓,两手都要硬。
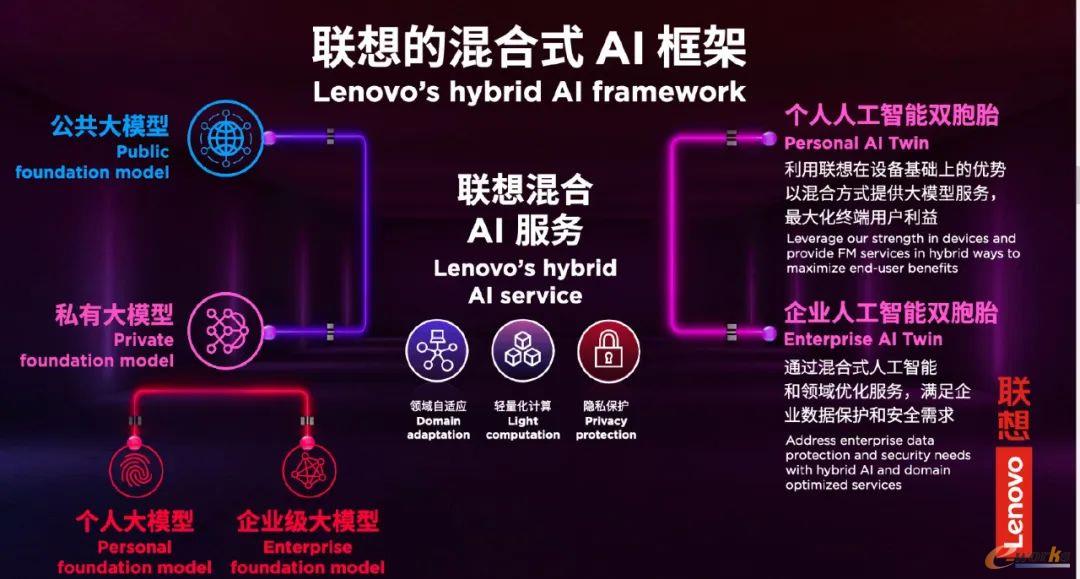
我们先来谈谈左手,如何增强大模型。联想倡导混合人工智能框架,是公有大模型和私有大模型的混合。从技术角度看,还有几个重要维度的混合。我这里谈四个维度的混合技术。这里有四个方程式,我敲一下黑板,大家今天下午参加大模型技术创新论坛的时候,我会考这四个方程式。
首先,小模型不会消失。今后一定是基于大模型和小模型混合的“意图理解”技术。大家知道信息论里面的熵entropy是度量信息量的。越有序,熵越小,越无序,熵越大。我们使用交叉熵cross entropy损失最小化原则,将意图理解任务最优地分配给大模型和小模型,从而兼顾精准度和复杂性。
第二,基于CPU、GPU、NPU混合调度的“异构计算”技术。今天,在大模型的训练和推理过程中,瓶颈往往不在于芯片算力,而在于数据传输。这个方程式是说,我们来同时优化计算负载和数据传输,使总体执行时间最短。
第三,基于模型微调(SFT) 与检索增强(RAG) 混合的“智能问答”技术。相信很多人都听过RAG和模型微调。这两种技术哪个更好呢?其实,这两种技术各有长短。这个方程比较复杂,我就不展开讨论了,这是用协同优化的方法,使RAG和模型微调相向而行,达到最优结果。
第四,基于硬件加密与全栈可信架构的混合“隐私安全”技术。光用硬件是不够的,光用软件也是不够的。我们知道,在前量子时代,我们是通过把一个非常大的整数进行质数分解进行加密。但是在后量子时代,这就不够了。这个方程式通俗地讲,就是通过在一个高维实数空间里进行因式分解来进行加密。可以看到,讲到的这4种混合式技术,需要端边云的协同,需要软件硬件的协同,需要传输与计算的协同。联想的新IT架构“端边云网智”正好为混合式技术的实现提供了强大支持。

我们刚才讲了两手都要抓,两手都要硬的左手:如何增强大模型,下面再来看看右手:如何打造智能体。我们知道,大模型不是万能的,但是没有大模型是万万不能的。所以位于C位的是大模型,相当于控制中枢。但是,光有大模型是不够的。
首先,我们要让智能体具有知道自己能力边界的能力。人就是一个智能体,人知道自己的能力边界。你如果问我茴香豆的茴字怎么写,这在我的能力边界内,我会告诉你是草字头,下面加一个回家的回。但是,如果你问我你可知道茴字有四种写法,我一听,这超出了我的能力边界,我会去寻找合适的工具,比如查字典,把答案告诉你。所以,我做为一个智能体,我知道自己的能力边界,也知道什么时候应该调用工具,调用什么样的工具。这就是智能体一个非常关键的能力。今天的大模型有时候会非常自信地告诉你一个错误答案。不是它想骗你,是因为它实在不知道自己知道什么和自己不知道什么。它不知道自己的能力边界在哪里。智能体其他的能力和功能,我就不一一展开了,包括主动感知,意图理解,复杂任务的分解,以及长短期的记忆机制。

总结一下,智能体基于大模型而又超越大模型。我刚才分享了我对大模型的两个观察和想法。下面让我们用热烈的掌声有请中国工程院院士,清华大学智能产业研究院院长,张亚勤博士来谈谈他对大模型的观点!”
张亚勤博士精彩分享:
“感谢芮勇的邀请!大家好,今天我很高兴参加联想创新科技大会,看到了联想在智能化时代的技术创新和产品创新。我很认同芮勇的观点,大模型表现出一些局限性,我们可以应用混合式的理念来提升它的能力,权衡算法精度、算力需求、内存容量、通讯带宽、隐私安全等因素。例如,公有模型和私有模型的结合,大模型和小模型的结合,传统机器学习和现代深度学习的结合,云侧、边侧、和本地设备部署的结合,CPU/GPU/NPU异构算力的结合,通用知识、领域知识、和个人知识的结合。我也很高兴地看到,联想的新IT架构很好地支撑了这些混合式AI技术的实现。

随着人们对大模型原理性认识的深入,种种改进方法也应运而生,逐渐发展出今天智能体。智能体的思维方式与行为方式更接近于人类,那也就可以期望它更加智能,真正成为人类的助手。对于个人应用来说就是真正的智能助理,把很多事情放心地交给智能助理来做。那么对于企业应用,因为现代的运营和管理系统变得越来越复杂,所以智能体技术可以发挥巨大潜力,把这些复杂的系统最大效率地调动起来,极大地提升运营效率和生产力水平。这与我所在的清华智能产业研究院的理念完全一致。我们跟联想已经在进行产学研合作,未来我期待我们能够携手发展人工智能技术,加速产业落地,共同推动智能化时代的转型。”
芮勇博士尾声致辞:
“感谢亚勤的分享!打造混合式AI框架,不仅仅是靠一个企业。联想非常希望与学术界,科技界,和企业界伙伴们一起,用最先进的混合式AI 技术,赋能千行百业,创造智能时代的新辉煌!”
 文章
文章
