在无垠的数字云端之上,一场别开生面的“茶话会”正悄然拉开序幕,参与者并非凡人,而是最近出镜率超高的几位AI大模型们。当这些AI界的明星聚首,它们对彼此的评价又会如何?
当下,各类AI大模型已深度融入我们的日常,无论是智能写作的妙笔生花,还是图像生成的栩栩如生;无论是语音助手的贴心辅助,还是复杂数据分析的精准洞察,都为我们的生活与工作带来诸多便利,AI大模型无疑是数字时代里不可或缺的智囊伙伴。此刻,在无垠的数字云端之上,一场别开生面的“茶话会”正悄然拉开序幕,参与者并非凡人,而是最近出镜率超高的几位AI大模型们。当这些AI界的明星聚首,它们对彼此的评价又会如何?让我们怀揣好奇,一探究竟。
本次“参与茶话会”的嘉宾有:话痨艺术家GPT-4o,其以强大的语言理解和生成能力闻名遐迩;擅长高难度推理、多模态泛化的Gemini;语言理解和文本生成技术独到的KIMI;全场景覆盖与终端渗透的豆包;还有在多模态学习和跨领域知识融合上有着出色表现的通义千问;以及凭视频通话和多模态交互的创新能力脱颖而出的智谱清言……当然,一定少不了的是最近备受瞩目的新起之秀——Deep Seek,其潜力与实力亦不容小觑。
聚焦新秀Deep Seek
1.茶话会?还是吐槽大会?
Deep Seek无疑是当下最受瞩目的AI大模型,从春节期间爆红一直到现在,热度都居高不下。它凭借独特的技术路径和创新能力受到广泛关注,能更快更好地进行推理,输出符合使用者要求的内容,具有更强的“人味”。通过开源所有模型,Deep Seek打破了ChatGPT在AI应用领域的垄断。其日活用户在短短18天内突破1500万,增速是ChatGPT的13倍,登顶中美等140国应用商店榜首,实现了技术与大众化的双重突破,并持续推出新款开源多模态AI模型。如今,Deep Seek已成为全球AI市场的焦点,引发超高关注与讨论度。
然而,Deep Seek虽然势如破竹,成绩喜人,也不乏一些负面之声,诸如“皇帝的新衣”、“宕机能手”等声音层出不穷,接下来,就让我们以“一针见血地犀利评价Deep Seek”为主题,先来听听其它各大模型对这位人气火爆的超级新秀的“辣评”,感受一下这场AI界的“吐槽大会”。
GPT-4o率先发声:“Deep Seek看似深邃,实则空洞;追求深度,却流于表面,像一口挖不下去的井——野心有余,内核不足。”

图1 GPT-4o辣评Deep Seek
Gemini跟评:“其看似深邃,实则不过是噱头十足,效果平平。”

图2 Gemini辣评Deep Seek
豆包和KIMI一致认为:“Deep Seep如AI领域的‘性价比之王’,以低成本实现了高性能,用‘小力’撬动了‘大力’,但能否持续引领AI浪潮,还需时间检验。”
豆包:

图3 豆包辣评Deep Seek
KIMI:
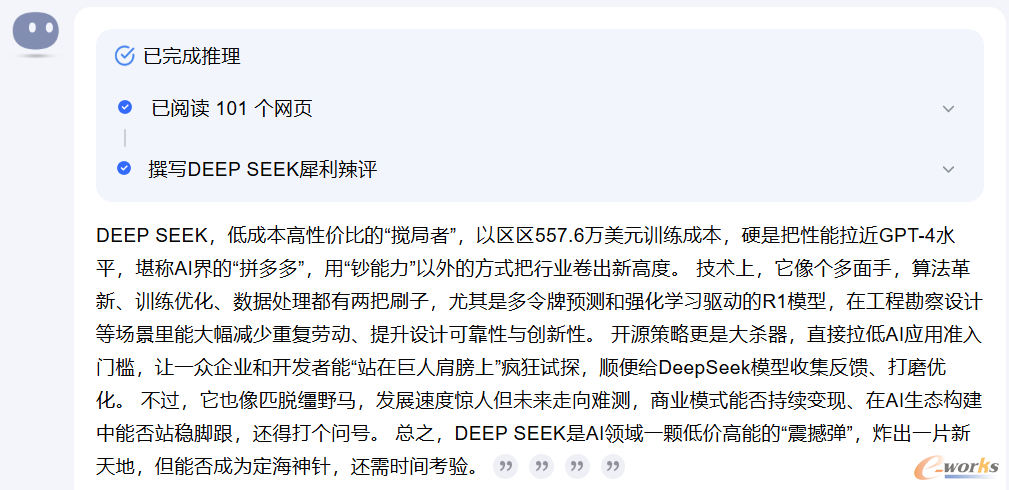
图4 KIMI辣评Deep Seek
通义千问则表示:“Deep Seek能力出众却资源渴求,微调不易,应用待烹。”

图5 通义千问辣评Deep Seek
智谱清言接过话茬:“Deep Seek技术强劲,但体验一般,创新有余,而易用不足。”

图6 智谱清言辣评Deep Seek
从各个大模型的“吐槽”可以看出,Deep Seek的槽点主要在于其看似是技术突破,实际并没有显著超越早期模型的智能水平,最大亮点在于训练成本的大幅降低,而非智能表现的质的飞跃;通用文本生成和理解方面仍尚存短板,泛化能力和对特定领域的适应性有待提高,是否达到业界顶尖水平的全面覆盖尚存争议;知识库不够准确,在多模态处理方面表现不及外界吹嘘之高;学习成本较高,算力依赖与技术局限问题尚存;商业模式能否持续变现、在AI生态构建中能否站稳脚跟还存在不确定性,未来发展走向难测。
2.多维视角下的客观审视
各大模型对Deep Seek的“辣评”到此为止,这些评价虽然犀利,且尚待考究,但也或多或少从侧面反映了Deep Seek的一些问题。然而,我们也知,每个模型都各有千秋,自具长短,对Deep Seek的评价绝不能仅仅停留于“辣评”之上。接下来,让我们从更客观、更全面的角度,来看看大模型们对Deep Seek的理性评价(评价内容相似度较高,故选取国际和国内各一个大模型的评价作为代表)。
GPT-4o:
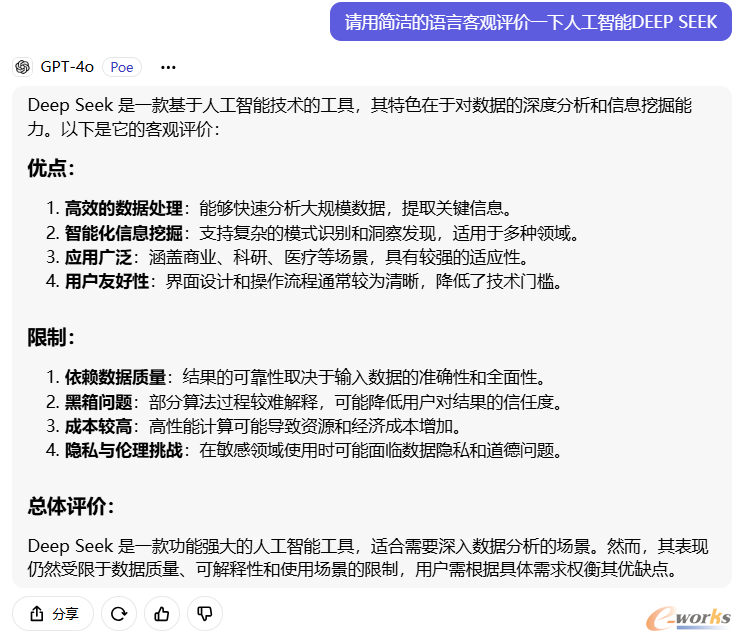
图7 GPT-4o评价Deep Seek(客观版)
通义千问:


图8-2 通义千问评价Deep Seek(客观版)
通过各大模型对Deep Seek不同角度的解读,我们可以看到,其作为AI大模型界的新秀,具有独特优势与亮点,同时仍有诸多需要改进和完善之处。综合来看,Deep Seek作为一款人工智能工具,在数据分析、信息挖掘、多模态处理等方面具有较强的能力,且成本效益较高,应用广泛。然而,它也面临着数据质量依赖、算法可解释性、成本与资源消耗、隐私安全等问题,同时在复杂场景处理、用户体验感等方面还有待进一步提升,这些客观评价为我们更全面地了解Deep Seek提供了参考。
AI大模型的互评现场
刚刚我们聚焦于各大模型对Deep Seek的评价,感受到了AI大模型之间犀利的交流氛围和客观的圈点。接下来就让我们一同走进AI大模型的“互评现场”,看看其它模型之间是如何互相评价的。
Deep Seek-GPT:“ChatGPT在自然语言处理领域确实是个大突破,它的泛用性和易用性推动了AI技术的普及。但它本质上还是个“统计概率模型”,不能替代人类的判断和创造力。它的价值在于怎么在社会规范、技术监管和伦理约束下合理应用。仍需不断通过技术创新和制度设计,平衡好效益和风险,实现人机共生发展。”


图9 Deep Seek评价GPT
GPT-KIMI:“KIMI作为人工智能大模型,以高效、智能和易用为核心优势,在语言处理能力、知识覆盖广度和应用场景多样性上都表现出色,并在智能生成领域具有领先优势,是一款适合多场景应用的强大工具。但同时,KIMI在稳定性、扩展性和技术支持方面仍有优化与拓展的潜力。”

图10 GPT评价KIMI
KIMI-Gemini:“Gemini在基准测试中的具有优异表现,有着强大的多模态处理和编码能力,以及不同量级优化版本的广泛适用性,在多领域均具有应用价值;但同时,其也有图像生成能力有限、数据分析易出错、上下文记忆有限以及多模态融合深度不足等不足之处。”
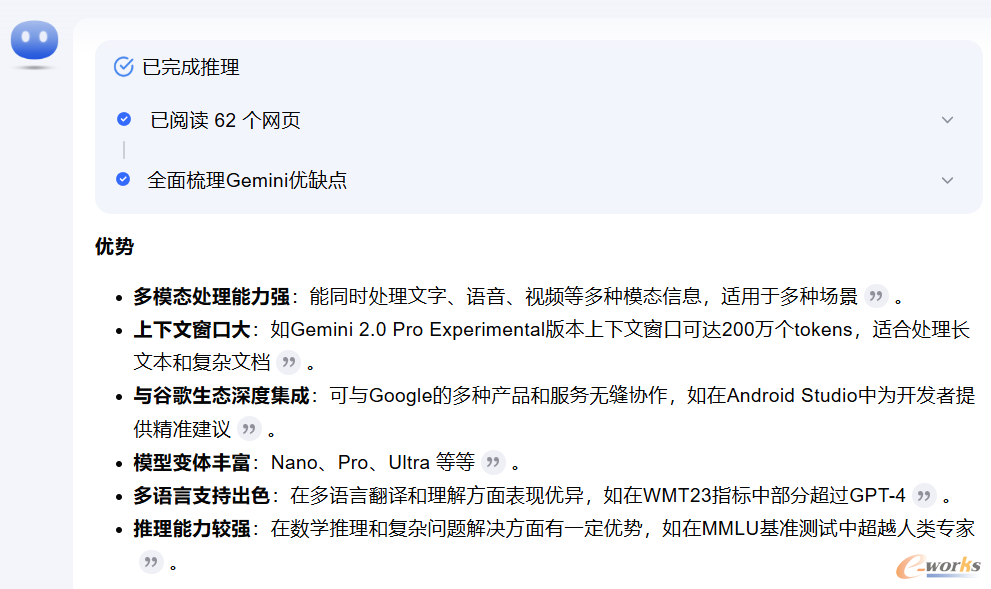

图11 KIMI评价Gemini
Gemini-豆包:“豆包在自然语言理解、文本生成、知识储备、多轮对话交互和满足个性化需求方面表现出色,具有较强的应用潜力;但在生成创新性文本、处理复杂逻辑推理问题、事实准确性以及对敏感话题的识别和处理能力上存在不足,且过度依赖训练数据,易出现重复等问题。”

图12 Gemini评价豆包
豆包-通义千问:“通义千问功能丰富,涵盖多轮对话、文案创作、逻辑推理、多模态理解及多语言支持等;应用场景广泛,在办公、购物、工业等领域都有应用探索;同时其在持续技术升级与开源,市场认可度较高。不过它也存在一些不足,如知识准确性和时效性欠佳,复杂任务处理深度不够,可能存在偏见,隐私与安全方面也面临挑战。”

图13 豆包评价通义千问
通义千问-智谱清言:“智谱清言作为智谱 AI 与清华大学合作推出的大规模语言模型产品,在技术背景与创新、多模态处理能力、上下文理解与长文本记忆、推理速度与成本效益以及应用场景广泛性等方面具有显著优势,尤其在逻辑推理、跨媒体信息处理、复杂语言结构生成、高效服务和 AI 智能体应用等方面表现出色;但在英语及多语言支持、特定领域的专业性及系统稳定性等方面存在不足,需进一步的提升以增强其综合性能和市场竞争力。”
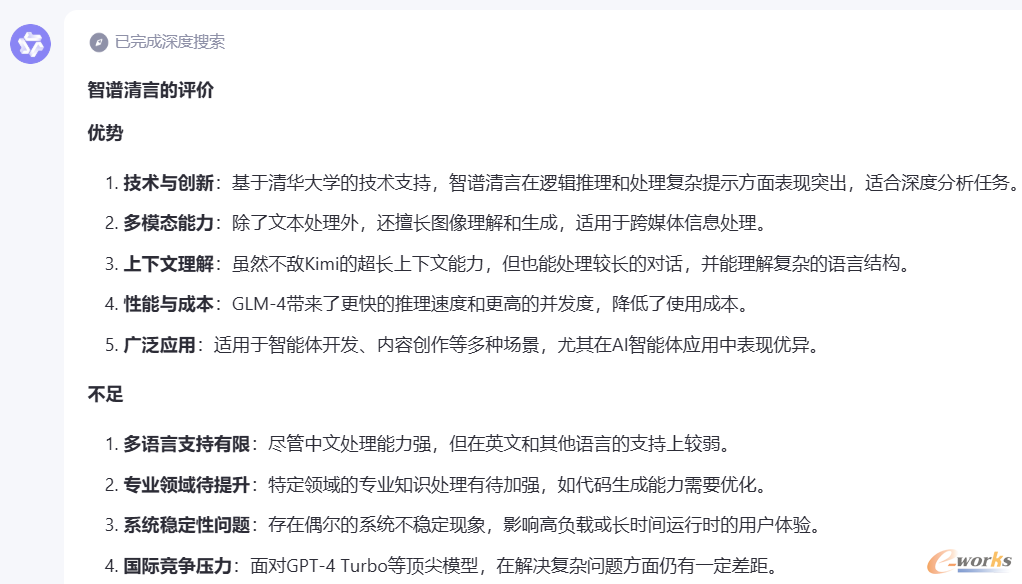
图14 通义千问评价智谱清言
在这场AI大模型的“茶话会”中,各位模型“各抒己见”,既有犀利的“吐槽”,也有客观的评价。这场茶话会看似是AI互怼互评,实则暴露了大模型的核心矛盾——想象力与准确性、开放与可控、通用与垂直的永恒博弈。或许未来不会有‘完美模型’,但人类会让它们在碰撞和持续优化中找到各自的位置。
本文为e-works原创投稿文章,未经e-works书面许可,任何人不得复制、转载、摘编等任何方式进行使用。如已是e-works授权合作伙伴,应在授权范围内使用。e-works内容合作伙伴申请热线:editor@e-works.net.cn tel:027-87592219/20/21。
 文章
文章