数据科学和机器学习对于未来的汽车工业来说,是非常关键的技术,因为这两项技术正在被用于汽车产品、汽车工艺优化和自动学习。在汽车工业研发、采购、物流、制造、市场运营、销售和售后、客户服务等环节,甚至更广泛的领域,工程技术人员正在探索应用人工智能技术的可能性。
著:(德)Martin Hofmann (奥地利)Florian Neukart (德)Thomas Bäck
编译:胡志强(中国汽车工程学会)
数据科学和机器学习对于未来的汽车工业来说,是非常关键的技术,因为这两项技术正在被用于汽车产品、汽车工艺优化和自动学习。在汽车工业研发、采购、物流、制造、市场运营、销售和售后、客户服务等环节,甚至更广泛的领域,工程技术人员正在探索应用人工智能技术的可能性。目前,已经可见的人工智能和数据科学应用案例已经说明这些技术给汽车工业带来的变革指日可待。
一、前言
数据科学和机器学习现在已经与人们的日常生活息息相关,这些技术已经被大量采用,随处可见,如汽车和手机中的语音识别功能、人脸识别、交通信号灯识别等,再如战胜了各国围棋高手的阿尔法狗机器人。在模式识别、研究和学习算法基础上建立的大数据分析技术已经能够洞察我们未知的领域,如各种生产工艺、系统、自然以及人类行为背后的动因,它打开了一扇大门,让我们进入了一个存在无限可能性的新世界。比如现在已经成为热点的无人驾驶汽车,对汽车驾驶者来说,通过汽车导航和巡航系统的帮助实现自动驾驶已经触手可及。
早在2015年底,特斯拉的创始人Elon Musk和丰田汽车几乎同时宣布,将投资十亿美元用于人工智能的研究和开发。在人工智能领域,这不过是冰山一角,但汽车行业未来发展趋势显而易见。工业互联、自动驾驶,以及不断从数据中学习并能做出最优决策的人工智能正在以颠覆性的革命性方式推进,这一趋势对很多工业的发展来说起着至关重要的作用,尤其是汽车工业。对很多国家来说,汽车工业是国民经济的支柱性产业之一。在不久的将来,汽车工业将融入这些新基因,即在数据科学和机器学习的帮助下,开发新的技术,提供新的服务,提升国际竞争力。
数据科学和人工智能技术带来的自动驾驶、智能工厂等汽车工业的愿景能否成为现实还有待时间来印证,但不管怎么样,我们坚信,这些技术的快速发展将引导汽车工业创建全新的产品、流程和服务,其中很多场景我们今天就能憧憬。
二、数据挖掘
人工智能和数据科学将数据应用分析分为四个层级(见图1),从低到高依次为“描述性分析”(发生了什么)、“诊断性分析”(为什么发生)、“预测性分析”(会发生什么)、“优化性分析”(应该怎么做)。高德纳公司之前使用“规范性分析”来表述最高层级,本文用“优化性分析”来替代,这样做的原因是,一项技术可以“描述”很多东西,而在公司内部的实现过程中,目标总是追求在规范性标准或质量标准的基础上做得“更优秀”。“优化”可以通过搜索算法得到支持,例如非线性案例中的“进化算法”和在更少见的线性案例下的运筹学方法。“优化性分析”获得了应用程序专家的支持,他们从数据挖掘过程中获取结果,并使用它们得出关于过程改进的结论。一个很好的例子是基于数据的决策树,程序专家可以运用自己的专业知识来理解和修正,然后以适当的方式实现。应用程序也可以用于优化的目的,当然,人始终会参与其中。中间两个级别也都是基于数据科学的技术,包括数据挖掘和统计,而“描述性分析”本质上是传统的商务智能概念(如数据库、联机分析处理)。
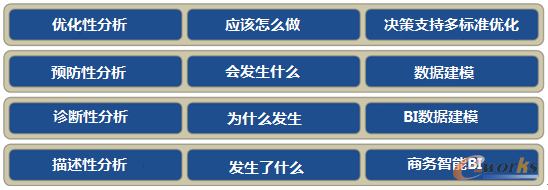
图1 数据分析的4个层级
有时候,数据挖掘需要相关应用程序对多个标准通同时进行优化,这意味着需要采用多标准优化方法,或者说多标准决策支持方法。这些方法用来在矛盾的目标之间找到最好的解决方案。例如成本与质量,或者风险与利润,前后两者经常发生矛盾,再举一个更具有技术性的例子,如车身的重量和车辆安全性能之间的矛盾。
这四个层级构成了一个框架,在这个框架中,可以将一个公司的数据分析能力和潜在收益进行分类。
传统的跨行业数据挖掘标准流程(CRISP-DM)不包括任何优化或决策支持(见图2)。
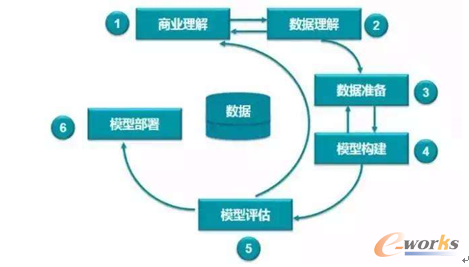
图2 跨行业数据挖掘标准流程
基于商业理解、数据理解、数据准备、建模和评估等子步骤,CRISP在业务流程中直接给出了的部署结果。在此,本文附加了一个额外的优化步骤,该步骤将包括多个标准优化和决策支持(见图3)。
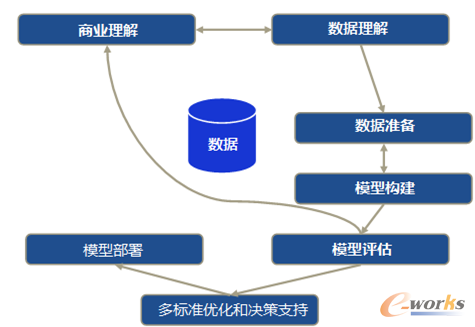
图3 优化后的跨行业数据挖掘标准流程
值得注意的是,原始的CRISP模型是数据科学家用来进行手工分析数据的迭代方法,这反映在业务理解和数据理解以及数据准备和建模之间的迭代中。然而,在评估步骤中引入相关应用程序专家来评估建模结果也可能导致流程必须从商业理解子步骤重新启动,如果需要合并其他数据的话,有必要执行部分或所有子步骤。
这一迭代流程背后的基本思想已经存在了20年,并且与时俱进,虽然只是部分兼容了大数据的策略,但仍适用于大多数应用。除了使用非线性建模方法(这种方法与通常来自统计建模的广义线性模型不同)和从数据中提取知识外,事实上数据挖掘的基本思想是,模型可以在算法的帮助下从数据中派生出来,而且这种建模过程大部分可以自动运行,因为算法自己能有效工作。
在需要创建大量模型的应用程序中,如基于历史数据对单个车型和市场的销售进行预测,自动建模起着重要的作用。在线数据挖掘的情况同样可以使用自动建模,如预测产品质量。自动建模不仅用于常规生产过程,还可用于某个单独流程发生变化时,例如一个新原料批次使用时。
这种类型的应用需要数据挖掘算法有自动生成数据,然后进行集成和处理的技术能力。此外,为更新模型并使它们作为创建在线应用最佳解决方案的基础,数据挖掘算法必须要能自动建模并自动优化。然后,这一建模和优化过程作为建议将被提供给过程专家参考,或者,尤其是在连续生产过程中,可直接用于控制各个过程。如果传感器系统也被直接集成到生产过程中用于实时收集数据,就会产生了一个自动学习的信息物理系统,这将帮助企业在生产过程中实现工业4.0的愿景。
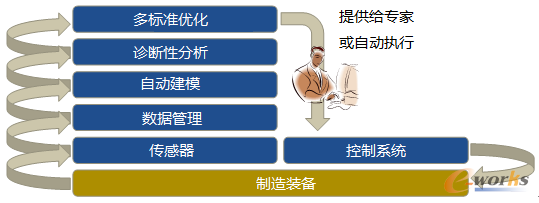
图4 基于优化分析的工业4.0构架
如图4所示,制造装备的数据通过传感器获得并归集到数据管理系统中,然后依据系统相关变量,如质量、目标值偏差、过程方差等建立预测模型预测系统输出结果。这一构架也可用于更多的机器学习选项,如预测性维护或者异常识别等。数据模型要被持续监测,如果发现过程漂移,则被自动修正。最后,多目标优化系统利用模型连续计算出系统控制的最佳设定值。构架中包含了人类过程专家,他们可以使用该系统推演出解决方案,在解决方案应用于原系统之前,过程专家也能够使用模型对方案进行评估。
为了区别于传统的数据挖掘,现在定义的大数据概念包含了三个基本特征(有时是四个或五个基本特征):量(Volume),即数据多少;速(Velocity),即资料输入、输出的速度;多样性 (Variety),即数据类型繁多而且是异构化的。大数据不再被归类于传统的关系数据库模式。此外还有准确性(Veracity),即数据中隐藏的巨大不确定性;价值密度(Value),即数据及其分析代表的公司业务流程价值。这两个特征通常作为附加特征。所以,区分以前的数据与大数据分析方法并不是只考虑数据量一个特征,而是要考虑其他技术特征,因此要使用新的分析方法,如使用Hadoop和MapReduce软件,并要调整数据分析算法,以使数据能够被保存和处理。此外,“内存数据库”也使得用传统的学习和建模算法对大数据进行存储处理成为可能。
可以看出,建立一个数据分析和建模方法的技术框架时,数据挖掘是大数据技术的一个子系统,而数据统计又是数据挖掘的一个子系统。并非每个应用程序都需要使用数据挖掘或大数据技术。但是,可以看到一个明显的趋势,随着越来越多的数据被采集并与公司的业务流程和诸多部门关联,使用数据挖掘和大数据的必要性显得越来越重要。可喜的是,常规的硬件构架和储存器空间已经足够大,完全可以满足大数据分析和存储的需要。
人工智能与数据科学在汽车工业中的应用(连载二)
人工智能与数据科学在汽车工业中的应用(连载三)
人工智能与数据科学在汽车工业中的应用之愿景篇
本文为e-works原创投稿文章,未经e-works书面许可,任何人不得复制、转载、摘编等任何方式进行使用。如已是e-works授权合作伙伴,应在授权范围内使用。e-works内容合作伙伴申请热线:editor@e-works.net.cn tel:027-87592219/20/21。
 文章
文章